In the past few years, digital technology was transforming many industries across the globe. The COVID-19 crisis has recently become a wakeup call for a lot of traditional corporations to rethink their business models. Agility is no longer just an option, but a business imperative to help companies survive in the current pandemic and thrive in the market ahead. A data-driven company has the competitive advantage to quickly adapt to any operational emergency and prepare for future business disruptions.
Data by itself does not have value. It becomes a company asset once it has been processed and analyzed to generate insights to be consumed for business decision making. Today’s Big Data environment consists of multiple data sources covering various aspects of the business. As a result, enterprise data is mostly distributed across disparate information systems, sources and silos, which need to be combined or consolidated for users to access and apply analytics.
Currently most data integration approaches are developed around the time consuming and labor-intensive Extract-Transform-Load (ETL) methodology. These practices move the data into a common format and location where it can be queried. During this process, the data is initially extracted from one or more sources. Then, it is cleansed, enriched, transformed on disk and ultimately loaded in batch into a target data warehouse with a significantly different schema before it can be consumed by analytics solutions or BI tools. The whole process is complex, expensive and slow.
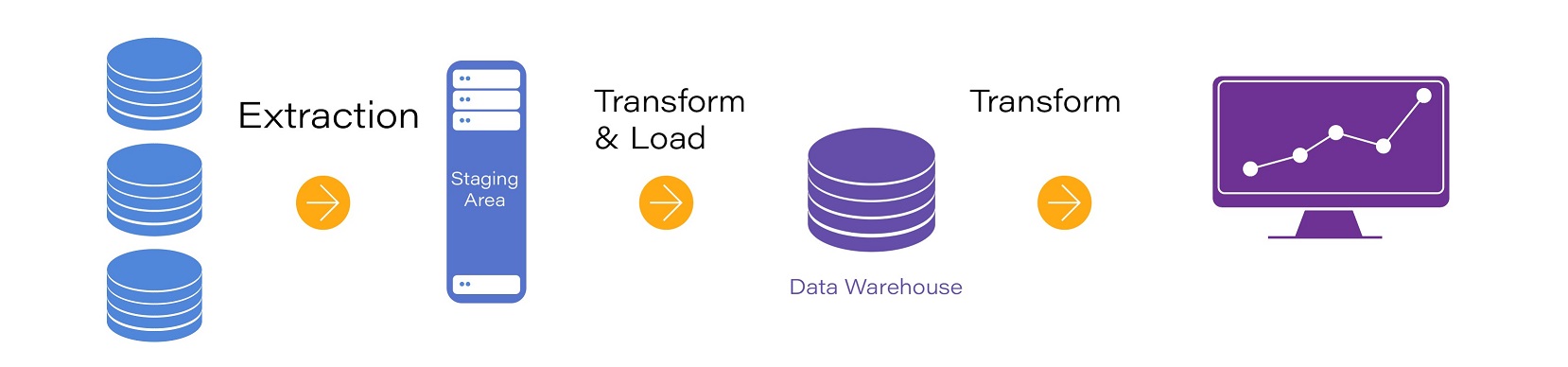 Figure 1. ETL Process
Figure 1. ETL Process
With the ETL approach, as any data load takes time, data latency can lead to performance bottlenecks . Besides being time-consuming, the ETL process is also resource intensive. It consumes significant CPU, memory, disk space, and network bandwidth to move large amounts of data in a batch-oriented manner. Therefore, this process is often scheduled to be run outside regular business hours. However, by the time the job is done, you will mostly be getting multiple out-of-date copies of the data. From the customer service perspective, customer experience will be negatively rated if questions cannot be answered instantly with real-time insights from data. From the IT perspective, the long-running batch jobs usually result in a data lake, which adds more complexity to respond to ad hoc queries. Making business decisions based on stale data diminishes a company’s competitive advantage and may even lead to risky business actions.
A data lake is a large storage repository that can hold a vast amount of raw data or slightly-prepared data in its native format. The idea is to have all data in a single location, which can be analyzed holistically later. While a data lake can hold huge volumes of data, managing the schema information and object naming across disparate data sources to provide a unified view of the entire data lake is a major challenge. As new data sources become available, the ETL process is in constant flux as new schema information must be accommodated and new processing must be added. As a result, the data lake continues to grow. A data swamp may appear later and become a serious issue when much more data is stored than is required for business analytical needs, making it even more difficult to be managed.
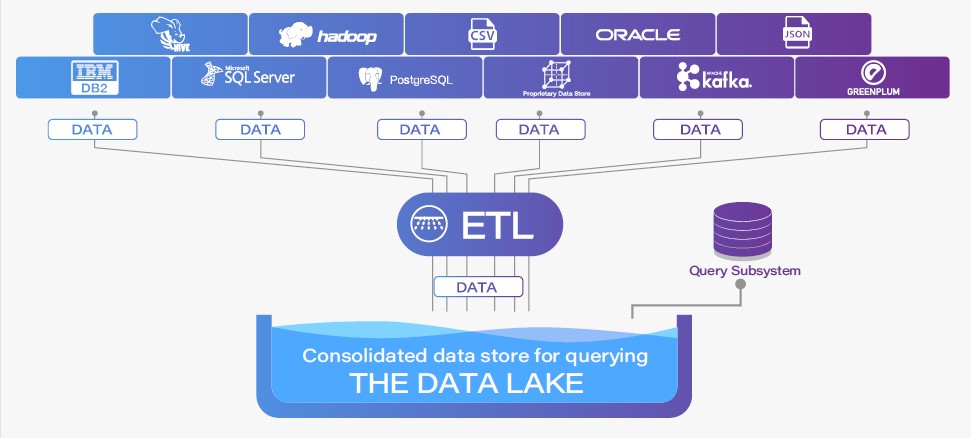
Figure 2. Big Data Current Environment
Is there an approach that can avoid the ETL process altogether? What if you could simply pull your data from each source without having to copy it somewhere else? What if you could see your disparate sources as a single schema? What if you could run queries through one source that accesses all your underlying data stores? What if these queries are run against the data in your data sources as those data sources are being constantly updated?
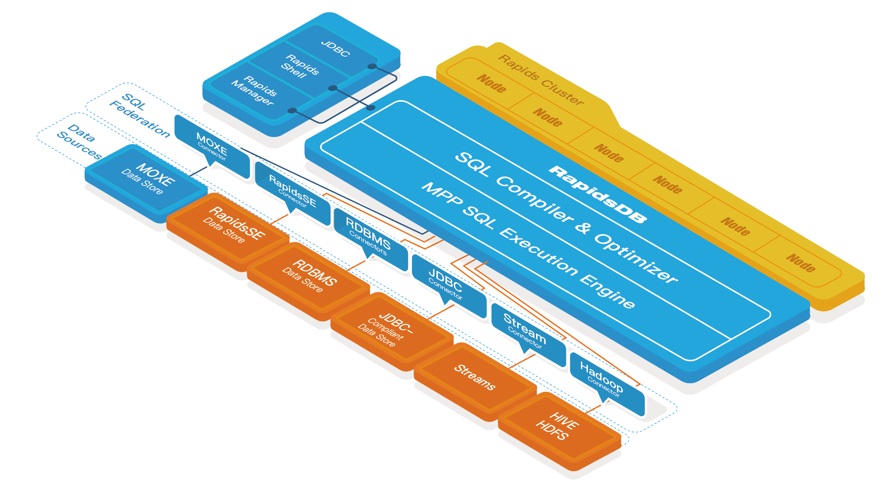
The Rapids Federation system is uniquely positioned to meet those very requirements. It is a logical grouping of a set of one or more RapidsDB Connectors. The RapidsDB Execution Engine is the distributed, in-memory, MPP query execution engine and through these Connectors the RapidsDB Execution Engine can get access to the data where it resides without the need for ETL.
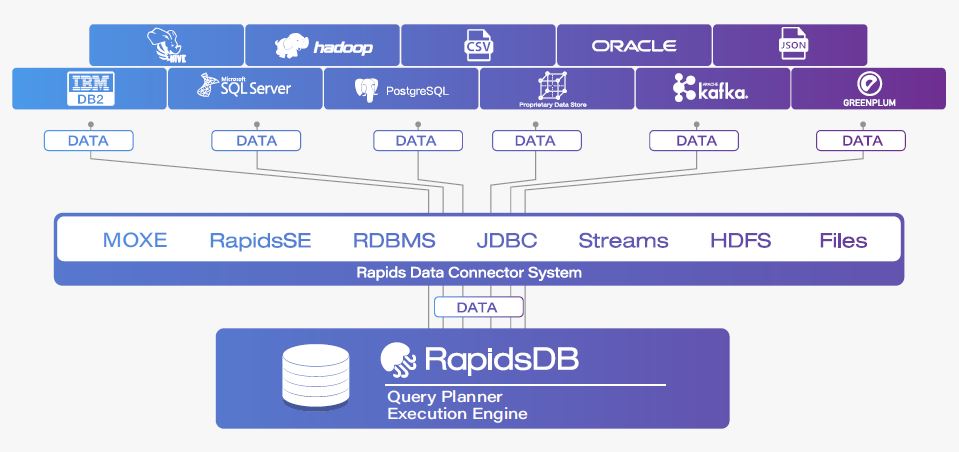
Figure 3. Data Integration with Rapids Federation
Rapids Federation completely eliminates data movement so that users can run queries that join multiple disparate databases without creating additional copies of data. The data will be presented as a single, federated database, where the user can easily identify and combine the data across any of the data sources. This approach abstracts away the complexity of the data preparation pipelines so that the user can focus more on analyzing data to solve business problems instead of spending tremendous amounts of time simply finding, cleansing and organizing data. It creates a single source of truth and provides the agility that is needed for analytical development to empower decision making.
Rapids Federation is fully ANSI SQL compatible, which means data across two or more disparate databases can be retrieved and combined using one single standard SQL query. Users are not required to learn different languages and tools of each data system to query the data. A federated query can reference and use different databases and schemas from entirely different systems in the same SQL statement.
In addition to traditional SQL query support, Rapids Federation also supports an embedded artificial intelligence (AI) capability called ParallelAI. ParallelAI leverages machine learning to empower users to build and train machine learning models to automate and accelerate the data-to-insights process. As machine learning algorithms get better while utilizing large amounts of data from the greatest possible variety of sources, Rapids Federation builds a robust foundation to help generate real-time insights and reliable predictions that a company can trust and base its decision on.
Through Rapids Federation, RapidsDB becomes an OLTP-and-OLAP compatible hybrid database. Relational and non-relational data sources, including real-time data, are able to be consolidated for real-time processing and analysis without being physically moved from one system to the other. It is a cost-effective way to break down data silos and accelerate the performance of legacy systems. Instead of being simply abandoned, the existing data infrastructure that a corporation has already invested largely in can be bridged and augmented with Rapids Federation to extend its capabilities. In the case of a hybrid data architecture, Rapids Federation can seamlessly connect on-premises with Cloud data sources where faster access to data is crucial to the business. As data is not duplicated and stays exactly where it is, no extra investment on hardware or Cloud space is needed to store copies of data.
The ETL approach might be workable in the past when data volume, velocity and variety were not significant. However, with the technology evolution, Big Data and AI are driving every company to become a data company, expanding the data landscape to an unprecedented scale. The ability to integrate various types of data from disparate and constantly updating sources to empower users to query any data from a central hub with the lowest latency and highest performance will fundamentally change the way that the world views and uses data. It repurposes data, gives it meanings, and turns it into a valuable asset that a company can leverage to better business processes, improve operational efficiencies, optimize customer experience and ultimately innovate itself.
In summary, the Rapids Federation system removes the complexity and cost of managing data by:
- Allowing data to be queried in-place without the need for ETL
- Enabling users to query and combine data across a wide variety of data sources using ANSI standard SQL
- Providing a single point of reference with uniform ANSI Standard SQL naming across all of the needed data sources
- Supporting the introduction of new data in existing sources or inclusion of new data sources as they become available
- Meeting the performance requirements to deliver results quickly and easily